Một phần của tài liệu MỐI LIÊN HỆ GIỮA ĐẶC ĐIỂM HỘI ĐỒNG QUẢN TRỊ VÀ HIỆU QUẢ HOẠT ĐỘNG CỦA DOANH NGHIỆP NIÊM YẾT TRÊN THỊ TRƯỜNG CHỨNG KHOÁN VIỆT NAM.PDF (Trang 26 -26 )
3. Phương pháp nghiên cứu
3.3. Mô hình và phương pháp nghiên cứu
3.3.1.
Đang xem: Mô hình gls là gì
Phương pháp nghiên cứu
3.3.1.1. Lựa chọn phương pháp ước lượng phù hợp
Để xem xét ảnh hưởng của các đặc điểm Hội đồng quản trị lên hiệu quả hoạt động doanh nghiệp, các phương pháp ước lượng trong luận văn được vận dụng trên cơ sở các nghiên cứu trước đây của Coles (2008), Eklund (2008), Bathula (2008), Ibrahim và Samad (2011), Darmadi (2011), Wintoki et al. (2012). Cụ thể, nghiên cứu sử dụng dữ liệu bảng (panel data) và hồi quy theo phương pháp bình phương nhỏ nhất kết hợp tất cả quan sát (Pooled OLS), phương pháp bình phương nhỏ nhất tổng quát (Generalized Least Square – GLS) kết hợp hiệu ứng ngẫu nhiên (Random effect), mô hình các ảnh hưởng cố định (Fixed effect model), phương pháp ước lượng dữ liệu bảng động 2 bước GMM (Dynamic Panel-data estimation, two-step system GMM).
Phương pháp Pooled OLS có giả định phương sai không đổi và không có tương quan chuỗi (serrial correlation), do vậy đòi hòi sai số mô hình trong mỗi thời điểm quan sát không tương quan với biến giải thích (Wooldridge, 2002; Bathula, 2008), và do vậy có thể làm giảm độ tin cậy của hệ số tương quan. Kiểm định White và kiểm định Breusch-Pagan được sử dụng để xem xét giả định phương sai không đổi5
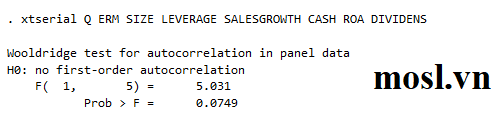
và kiểm định Wooldridge cho vấn đề tương quan chuỗi6.
Phương pháp ước lượng bình phương nhỏ nhất tổng quát (Generalized Least Square – GLS) kết hợp hiệu ứng ngẫu nhiên (Random effect) (gọi tắt là REM) cho phép sự xuất hiện của hiện tượng phương sai thay đổi và tự tương quan do vậy có thể làm tăng độ tin cậy của tham số ước lượng (Bathula, 2008). Giả định căn bản của phương pháp này là sai số mô hình độc lập với biến giải thích (Diggle et al., 2002).
5
Giả thiết Ho: Không có hiện tượng tự tương quan. 6
Kiểm định do Drukker (2003) đề xuất. Giả thiết Ho: Không có hiện tượng tương quan chuỗi.
Phương pháp ước lượng mô hình hiệu ứng cố định (Fixed effect model – FEM) được sử dụng khá rộng rãi trong các nghiên cứu về quản trị doanh nghiệp và hiệu quả hoạt động của công ty (Wintoki et al., 2012). Phương pháp này có thể giúp cải thiện những yếu tố gây ước lượng thiên lệch đến từ tính không đồng nhất chưa quan sát (unobservable heterogeneity), tuy nhiên để đổi lấy điều này, thì FEM đòi hỏi giả định ngoại sinh mạnh (strict exogeneity). Thông qua kiểm định Hausman so sánh giữa REM và FEM, nếu kiểm định cho thấy mô hình FEM hiệu quả hơn, thì điều này phản ánh các giả định của REM đã bị vi phạm (Ebbes, 2004). Để kiểm định giả thiết tồn tại sự ngoại sinh mạnh, nghiên cứu sử dụng phương pháp của Wintoki et al. (2012), theo đó nếu các đặc tính của HĐQT có ảnh hưởng đến hiệu quả hoạt động của doanh nghiệp trong quá khứ, thì giả định của FEM bị vi phạm. Nếu giả định của FEM không bị vi phạm, phương pháp ước lượng này sẽ hạn chế được vấn đề nội sinh và giúp kết quả mô hình đáng tin cậy. Phương pháp tiếp cận dữ liệu bảng động GMM hai bước (two-step system GMM) được đề xuất bởi Holtz-Eakin et al. (1988) và Arellano và Bond (1991), giúp xem tất cả các biến giải thích là nội sinh và sử dụng giá trị quá khứ của các biến làm các biến công cụ (Pathan và Faff, 2012; Wintoki et al., 2012)7 từ đó giúp đo lường hiệu quả ảnh hưởng của quản trị doanh nghiệp lên hiệu quả hoạt động (Wintoki et al., 2012). Phương thức tiếp cận của GMM hai bước như sau:
(1) tạo một phương trình của sai phân bậc 1 của mô hình ước lượng và
7
Ngoài ra, theo Baum et al. (2003), các biến công cụ sử dụng trong mô hình này được tạo lập trên nền tảng hồi quy IV (Instrumental Variables), ý tưởng của phương pháp hồi quy này là tìm một bộ biến công cụ thỏa mãn hai điều kiện (1) tương quan với các biến giải thích và (2) không tương quan với phần dư. Nhờ sử dụng nền tảng hồi quy IV nên sự tương quan giữa các biến giải thích và phần dư sẽ bị loại bỏ.
(2) ước lượng phương trình sai phân bằng phương pháp GMM sử dụng giá trị độ trễ của các biến giải thích làm biến công cụ (tức là sử dụng độ trễ của các đặc điểm HĐQT)8.
Phương pháp ước lượng sử dụng sai phân và độ trễ của các biến này đòi hỏi thỏa mãn hai giả định căn bản để biến công cụ có hiệu lực: (1) các biến công cụ là ngoại sinh và (2) không có hiện tượng tự tương quan trong sai phân phần dư (Mileva, 2007). Để kiểm định các giả định của mô hình, tác giả sử dụng kiểm định AR(1) và AR(2) để kiểm tra vấn đề tự tương quan bậc 1 (first order) và bậc 2 (second order) trong sai phân phần dư, kiểm định Hansen’J để kiểm tra sự hiệu lực của các biến công cụ (Mileva, 2007; Roodman, 2009; Wintoki et al., 2012; Pathan và Faff, 2012). Nếu kết quả kiểm định cho thấy sai phân bậc 1 có hiện tượng tự tương quan nhưng sai phân bậc 2 không tự tương quan (kiểm định AR(1) và AR(2) đều có giả thiết H0: không có tự tương quan) và kiểm định Hansen’J cho thấy chấp nhận giả thiết H0: các biến công cụ ngoại sinh (Mileva, 2007) thì mô hình ước lượng theo phương pháp này phù hợp.
Hình 3.1: Tóm tắt các kiểm định sử dụng để xem xét sự phù hợp của từng phương pháp ước lượng
8
Wintoki (2012) cho rằng phương pháp ước lượng dữ liệu bảng động GMM có ưu điểm hơn Pooled OLS và FEM ở chỗ (1) đưa ảnh hưởng hiệu ứng cố định vào mô hình để hạn chế vấn đề không đồng nhất chưa quan sát (unobservable heterogeneity), (2) cho phép các đặc điểm HĐQT bị ảnh hưởng bởi giá trị quá khứ của chính các đặc điểm này, và (3) cho phép các đặc điểm HĐQT bị ảnh hưởng bởi hiệu quả hoạt động của doanh nghiệp trong quá khứ. Chính nhờ điều này giúp mô hình không cần đưa thêm các biến công cụ bên ngoài,
3.3.1.2. Phân tích kết quả hồi quy
Sau khi lựa chọn được phương pháp ước lượng phù hợp, tác giả thực hiện hồi quy cho toàn mẫu, sau đó chia mẫu ra thành nhóm các công ty có hiệu quả hoạt động cao và các công ty có hiệu quả hoạt động chưa cao dựa trên chỉ số Tobin’s Q (Tobin’s Q lớn hơn 1 là nhóm công ty tăng trưởng cao và ngược lại) và chỉ số ROA (nhóm công ty có ROA cao hơn ROA trung vị thì có hiệu quả hoạt động tốt và ngược lại). Cách phân loại này được vận dụng theo nghiên cứu của nhóm tác giả Moradi (2012)9.
3.3.1.3.
Xem thêm: Bí Mật Những Sứ Mệnh Của Cẩm Y Vệ, Sự Biến Mất Bí Ẩn Của Tổ Chức Cẩm Y Vệ
Phân tích sơ bộ dữ liệu mẫu
Ngoài ra, để phân tích sơ bộ dữ liệu, mẫu các công ty được phân loại lần lượt theo từng tiêu chí về đặc tính hội đồng quản trị thành 02 nhóm: có đặc tính
9
Nghiên cứu của Moradi et al.(2012) xem xét mối liên hệ giữa các đặc tính của hội đồng quản trị và quản lý thu nhập (đo lường bởi tổng dòng tiền dự thu của doanh nghiệp). Trong nghiên cứu này các tác giả phân loại dòng tiền dự thu thành 03 cấp: cao (nhóm 67% – 100% dòng tiền cao nhất), trung bình (33%-66%) và thấp (0%-33%), từ đó so sánh kết quả hồi quy giữa các nhóm để đưa ra kết luận. Trong luận văn này, vì mẫu dữ liệu có kích cỡ nhỏ nên tác giả chỉ phân loại hiệu quả hoạt động doanh nghiệp làm 2 nhóm để tiến hay hồi quy.
Pooled OLS • Kiểm định White, Breusch-Pagan • Kiểm định Wooldridge Random Effect • Kiểm định Hausman Fixed effect model • Kiểm định hệ số tương quan biến độ tới Dynamic Panel data two step system GMM • Kiểm định AR(1), AR(2) • Kiểm định Hansen” J
cao/thấp dựa trên giá trị trung vị của nhóm đó (chẳng hạn nhóm có tỷ lệ thành viên nữ cao và nhóm có tỷ lệ thành viên nữ thấp) đối với các đặc tính: độ tuổi trung bình, quy mô HĐQT, tỷ lệ thành viên nữ, tỷ lệ thành viên có trình độ thạc sỹ trở lên, tỷ lệ thành viên người nước ngoài và tỷ lệ sở hữu của HĐQT. Đối với đặc tính kiêm nhiệm chức danh, mẫu được phân thành nhóm có kiêm nhiệm và nhóm không kiêm nhiệm. Sau khi phân nhóm, tác giả lần lượt xem xét sự khác biệt trong hiệu quả hoạt động giữa 02 nhóm dựa trên các tiêu chí phân loại. Kiểm định t (t-test) được sử dụng để xem xét hiệu quả hoạt động giữa các nhóm có khác biệt có ý nghĩa thống kê hay không. Phương pháp này được áp dụng trước đó trong nghiên cứu của Pei Sai Fan (2012).
FEM là gì? Fem hay còn được gọi là mô hình tác động cố định (Fixed Effects Model) là một trong các dạng phổ biến của mô hình dữ liệu bảng (Panel data model) bên cạnh mô hình tác động ngẫu nhiên REM (Random Effects Model). Mô hình FEM – hồi tác động cố định (Fixed-effects) và REM – tác động ngẫu nhiên (random-effects) được sử dụng trong phân tích dữ liệu bảng (hay còn gọi là dữ liệu dài: longitudinal data).
Bài viết dưới anhhung.mobi xin giới thiệu toàn bộ khái niệm và các kiểm định xoay quanh các mô hình Pooled OLS là gì?, FEM là gì?, REM là gì?, GLS và FGLS là gì? gồm Hausman Test, Breusch – Pagan LM test, F Test, Chow Test,…
1. Dữ liệu bảng Paneldata là gì?
Dữ liệu bảng là tập hợp của hai loại dữ liệu chuỗi thời gian (time – series) và dữ liệu chéo (Cross-setional).
Tham khảo thêm bài viết chuyên sâu về Dữ liệu bảng – panel data là gì? của anhhung.mobi nhé!
Mô hình hồi quydữ liệu bảng điều khiểnchungcó dạng:






Các giả định của mô hình hiệu ứng cố định và hiệu ứng ngẫu nhiên bị vi phạm trong cài đặt này.Thay vào đó, các học viên sử dụng một kỹ thuật như côngcụ ước lượng Arellano-Bond.
6.2. Ước lượng LSDV (Least Squares Dummy Variable Estimator) của OLS
Ước lượng LSDV (Least Squares Dummy Variable Estimator) là ước lượng biến giả bình phương tối thiểu là một dạng của ước lượng OLS.
Quá trình thực hiện ước lượng l
SDV theo 2 bước như sau:
Bước 1: Tạo một biến giả tương ứng với một đối tượng trong mẫu. Bước 2: Hồi quy OLS biến phụ thuộc Y theo N-1 biến giả và các biến giải thích.
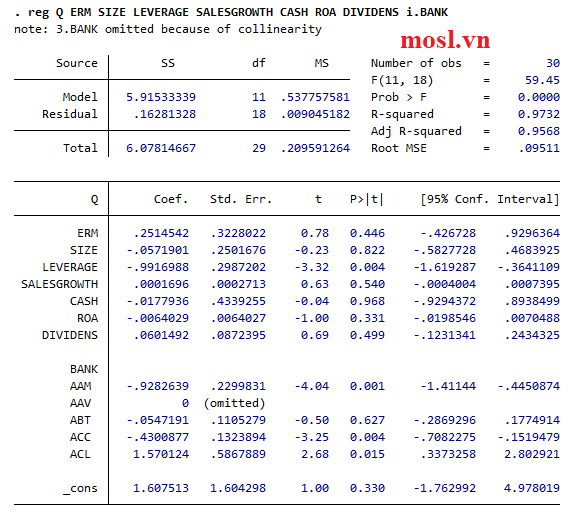
Ở dữ liệu này ta có 6 công ty, thì ta sẽ tạo ra 6 biến giả, và sẽ đưa 4-1 biến giả này vào hồi quy OLS đơn giản với lệnh i.công ty (STATA tiện quá nhỉ!) thêm vào code khi hồi quy mô hình OLS ban đầu.
Xem thêm: Phần Mềm Wincc Basic V15 – Giới Thiệu Phần Mềm Wincc
6.3. Các cách khác để lựa chọn giữa FEM và REM
Rõ ràng, một trong những thách thức của chúng ta khi phân tích dữ liệu mảng là lựa chọn REM hay FEM là gì khi phân tích? Về vấn đề này, Judge et al. (2007) chỉ ra một số dấu hiệu như cho việc lựa chọn mô hình như sau:
Nếu T là lớn và N là nhỏ thì rất có thể không tồn tại khác biệt lớn giữa các ước lượng thu được từ REM và FEM. Sự lựa chọn mô hình lúc này chỉ đơn thuần là căn cứ vào sự thuận tiện khi tính toán. Theo tiêu chí này thì FEM thường được ưu tiêu hơn.Khi T là nhỏ và N là lớn thì các ước lượng thu được từ hai phương pháp có thể khác biệt đáng kể. Nhắc lại rằng trong mô hình REM, βi =γ1 + εi với đại diện cho bộ phận sai số ngẫu nhiên ứng với cá thể thứ i trong mẫu nghiên cứu. Trong khi đó, ở mô hình FEM thì ta coi βi là bộ phận cố định chứ không phải là biến ngẫu nhiên. Cách tiếp cận FEM là phù hợp nếu chúng ta tin tưởng mạnh mẽ rằng các cá thể trong mẫu nghiên cứu không được lựa chọn ngẫu nhiên từ một tổng thể lớn hơn. Ngược lại, nếu các cá thể trong mẫu được lựa chọn ngẫu nhiên thì REM là phù hợp hơn. Vì trong tình huống này các thống kê suy luận là không có điều kiện (unconditional).Nếu bộ phận sai số ngẫu nhiên εi và một hay một số biến độc lập là tương quan thì các ước lượng thu được từ FEM là các ước lượng chệch (biased) trong khi đó các ước lượng thu được từ FEM là các ước lượng không chệch (unbiased).Nếu T nhỏ và N là lớn và các giả định nền tảng cho REM là đúng thì các ước lượng thu được từ REM là hiệu quả hơn so với các ước lượng thu được từ FEM (Taylor, 1980).
Tuy GLS là mô hình cao cấp nhất sau khi khắc phục các khuyết tật như phương sai thay đổi và tự tương quan nhưng nó vẫn chưa thể khắc phục được hiện tượng nội sinh và phải bằng kiểm định GMM thì ta mới khắc phục được vấn đề này. Nên nhớ đón xem toàn bộ vấn đề xoay quanh mô hình GMM của anhhung.mobi tại đây nhé!
7. Tổng kết
Tổng hợp lại kiến thức anhhung.mobi đã cung cấp đến độc giả đơn giản như sau:
1. Khái niệm mô hình REM và FEM là gì?
2. Hồi quy mô hình FEM và REM trong Stata
3. Tiến hành lựa chọn 3 mô hình FEM, REM, POOLED OLS bằng kiểm định Hausman Test, Breusch – Pagan LM, Chow Test …